


DEX文件
Google 为 Android 中的 Java 代码专门设计了对应的可执行文件 DEX(Dalvik eXecutable File),适用于手机这样的内存低和处理器性能较差的移动平台。
数据类型
前缀u表示无符号,s表示有符号
| 类型 | 含义 |
|---|---|
| u1 | 表示1byte的无符号数 |
| u2 | 表示2bytes的无符号数 |
| u4 | 表示4bytes的无符号数 |
| u8 | 表示8bytes的无符号数 |
| sleb128 | 有符号LEB128,可变长度为1~5bytes |
| uleb128 | 无符号LEB128,可变长度为1~5bytes |
| uleb128p1 | 无符号LEB128值 + 1,可变长度为1~5bytes |
LEB128
LEB128(“Little-Endian Base 128”)表示任意有符号或无符号整数的可变长度编码。该格式借鉴了 DWARF3 规范。在 .dex 文件中,LEB128 仅用于对 32 位数字进行编码。
每个 LEB128 编码值均由 1-5 个字节组成,共同表示一个 32 位的值。每个字节均已设置其最高有效位(序列中的最后一个字节除外,其最高有效位已清除)。每个字节的剩余 7 位均为载荷,即第一个字节中有 7 个最低有效位,第二个字节中也是 7 个,依此类推。对于有符号 LEB128 (sleb128),序列中最后一个字节的最高有效载荷位会进行符号扩展,以生成最终值。在无符号情况 (uleb128) 下,任何未明确表示的位都会被解译为 0。
dex文件结构
整体结构
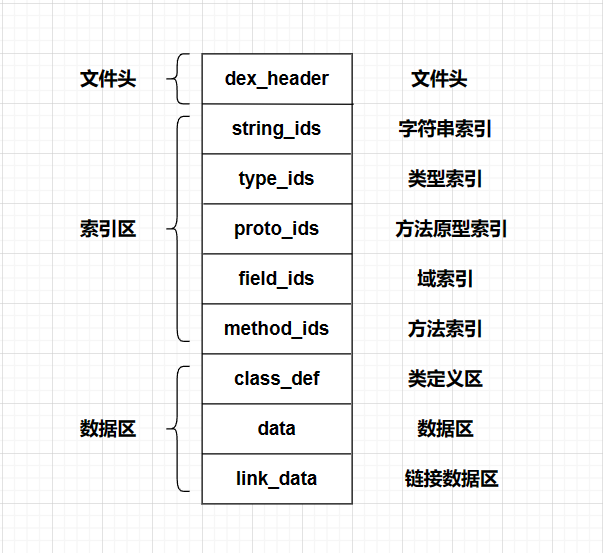
DEX 文件头
| 字段 | 偏移量 | 长度 | 解释 |
|---|---|---|---|
| magic | 0x0 | 8 | 魔数字段,格式如“dex/n035/0”,其中035表示dex结构的版本号 |
| checksum | 0x8 | 4 | dex文件的校验和,通过它来判断dex文件是否被损坏或篡改 |
| signature | 0xC | 20 | 文件剩余内容(除 magic、checksum 和此字段之外的所有内容)的 SHA-1 签名(哈希);用于对文件进行唯一标识 |
| fileSize | 0x20 | 4 | 整个dex文件的大小(byte单位) |
| headerSize | 0x24 | 4 | dex_header(即DexHeader结构体)的大小 |
| endianTag | 0x28 | 4 | 指定dex运行环境的cpu字节序(即大端还是小端),有小端字节序(ENDIAN_CONSTANT = 0x12345678)和大端字节序(REVERSE_ENDIAN_CONSTANT = 0x78563412)两种。 |
| linkSize | 0x2C | 4 | 链接段的大小 |
| linkOff | 0x30 | 4 | 链接段的文件偏移量 |
| mapOff | 0x34 | 4 | dex_map_list(即DexMapList结构体)的文件偏移量 |
| stringIdsSize | 0x38 | 4 | string_ids区中的字符串索引的个数 |
| stringIdsOff | 0x3C | 4 | string_ids区的文件偏移量(一般与headerSize相等) |
| typeIdsSize | 0x40 | 4 | type_ids区中的类型索引的个数 |
| typeIdsOff | 0x44 | 4 | type_ids区的文件偏移量 |
| protoIdsSize | 0x48 | 4 | proto_ids区中的方法原型索引的个数 |
| protoIdsOff | 0x4C | 4 | proto_ids区的文件偏移量 |
| fieldIdsSize | 0x50 | 4 | field_ids区中的域索引的个数 |
| fieldIdsOff | 0x54 | 4 | field_ids区的文件偏移量 |
| methodIdsSize | 0x58 | 4 | method_ids区中的方法索引的个数 |
| methodIdsOff | 0x5C | 4 | method_ids区的文件偏移量 |
| classDefsSize | 0x60 | 4 | class_def区中的类的个数 |
| classDefsOff | 0x64 | 4 | class_def区的文件偏移量 |
| dataSize | 0x68 | 4 | data区的大小,必须为4字节的整数倍 |
| dataOff | 0x6C | 4 | data区的文件偏移量 |
string_ids(DexStringId列表)
StringIds 区段包含stringIdsSize个DexStringId结构,其结构如下:
1 | struct DexStringId { |
可以看出 DexStringId 中存储的只是每一个字符串的相对偏移。此外,每一个偏移占据 4 个字节,字符串部分一共会占据 4*stringIdsSize 个字节。
在对应的偏移处,字符串是使用 MUTF-8 格式存储的,其开头存储了之前我们所说的 LEB128 类型的变量,表示字符串的长度,之后紧跟着的就是字符串,之后以\x00 结尾,字符串的长度不包含\x00。
type_ids(DexTypeId列表)
type_ids 区索引了 java 代码中使用的所有类型(类、数组或基本类型),此列表必须按 string_id 索引进行排序,并且不能重复。string_ids[type_ids]就是地址。
1 | struct DexTypeId { |
proto_ids(DexProtoId列表)
Proto id 字段主要是针对于 java 中的方法原型而设计的,这里面主要包含了一个方法声明的返回类型与参数列表,对于方法名尚未涉及。其主要包含以下三个数据结构
1 | struct DexProtoId { |
field_ids(DexFieldId列表)
field id 区主要是针对于 java 中每个类的字段而设计的,DexFieldId结构体指明了成员变量所在的类、类型以及变量名。,主要涉及到以下数据结构
1 | struct DexFieldId { |
method_ids(DexMethodId列表)
method id 区是直接为 java 中的方法而设计的,其包含了方法所在的类,方法的原型,方法的名字。
1 | struct DexMethodId { |
class_def(DexClassDef列表)
classDefsSize 表明 class def 区域的大小,classDefsOff 表明 class def 区的偏移。
该区是为 java 中的类而设计的,包含以下的数据结构,相关信息如下
1 | struct DexClassDef {// 类的基本信息 |
DEX map section
DexHeader 中的 mapOff 字段给出了 DexMapList 结构在 DEX 文件中的偏移。当 Dalvik 虚拟机解析 DEX 文件后的内容后,会将内容映射到 DexMapList 数据结构,可以说该结构描述了对应的 DEX 文件的整体概况。其具体代码如下
1 | struct DexMapList { |
定位方法的字节码
解析dex
解析dex获取类名
获取类名的索引l:类名索引|—>type表索引|—>字符串表索引
解析dex获得方法名
获取方法的索引,再根据方法的索引去找字符串的索引
解析dex获得签名
获取返回值签名:类的索引|—>pro表的索引|—->type索引—–>字符串表索引
获取参数签名:类的索引|—->pro表的索引l,并计算结构体—->type表的索引|—–>字符串表的索引
假设我们需要解析 DEX 文件中的某个方法的字节码,我们会经历以下步骤:
步骤 1:读取文件头,获取段的绝对偏移
- 从文件头中读取
class_defs_offset和class_defs_size,找到类定义表的起始绝对偏移。 - 假设
class_defs_offset = 0x1000。
步骤 2:定位类定义,读取类的相关偏移
在类定义表中,每个
class_def_item包含一个class_data_off,表示类数据的相对偏移。假设
class_data_off = 0x200。计算类数据的绝对偏移:
\text{类数据绝对偏移} = \text{class_defs_offset} + \text{class_data_off} = 0x1000 + 0x200 = 0x1200
步骤 3:定位方法的 code_item 偏移
在类数据中,每个方法对应一个
code_off,表示方法字节码的相对偏移。假设
code_off = 0x300。计算方法代码的绝对偏移:
\text{方法代码绝对偏移} = \text{类数据绝对偏移} + \text{code_off} = 0x1200 + 0x300 = 0x1500
步骤 4:读取字节码
- 通过计算的绝对偏移(
0x1500),读取code_item的结构,解析方法的字节码和其他信息。
| 名称 | 含义 | 示例 |
|---|---|---|
| 头相对偏移 | 各数据段相对于文件头部(起始位置)的偏移 | class_defs_offset = 0x1000 |
| 头绝对偏移 | 文件头部的绝对偏移,通常为 0 |
文件头绝对偏移 = 0x0 |
| 具体定位相对偏移 | 数据段内某条目的偏移,描述其相对于段起始位置的偏移 | class_data_off = 0x200 |
| 具体定位绝对偏移 | 通过段绝对偏移和相对偏移计算出的全局偏移,用于文件中的精确定位 |
odex
ODEX(Optimized DEX)文件是 Android 系统中经过优化的 .dex 文件,是 Android 应用在安装或运行时生成的文件,用于提高应用的启动速度和运行效率。
来源与作用
. 来源
- 原始 DEX 文件:Android 应用的核心字节码文件是
.dex文件,存储在 APK(Android Package)中,供 Dalvik 或 ART 虚拟机执行。 - ODEX 文件生成:当应用安装到设备上时,Android 系统会将 APK 中的 .dex文件进行优化处理,生成 ODEX 文件。
- 优化过程是通过
dexopt工具完成的(在 Dalvik 虚拟机时代)。 - 在 ART(Android Runtime)下,对应的优化文件是
.oat文件。
- 优化过程是通过
** 作用**
- 启动优化:
- 通过将
.dex文件中的字节码优化为特定硬件架构的更高效格式,加快应用启动速度。
- 通过将
- 减少内存占用:
- 提供了一种共享库的机制,使得同一个类的实例可以在不同进程间共享。
- 安全性:
- 部分设备和 ROM 会将 ODEX 文件存储在特定的系统分区中,防止篡改,增强安全性。

odex文件头
1 | struct DexOptHeader { |
依赖库
1 | struct Dependences{ |
辅助数据
该部分有三个Chunk块,它们被Dalvik虚拟机加载到一个称为auxillart的段中。这三个Chunk块,都以一个header联合体开头,定义如下:
1 | union{ |
union是联合体,里面的变量共用同一空间,所以大小为8字节。其中type字段为枚举常量,具体如下:
1 | eum{ |
size字段表示需要填充的数据的字节数。
ChunkClassLookup结构,Dalvik虚拟机通过DexClassLookup结构来检索dex文件中所有的类。
1 | struct ChunkClassLookup{ |
ChunkRegisterMapPool结构体:
1 | struct ChunkRegisterMapPool { |
ChunkEnd结构体:
1 | struct{ |
ODEX 文件的生成与使用流程
** 在 Dalvik 虚拟机时代**
- APK 安装时生成:
- 在 Dalvik 虚拟机上,系统会在安装 APK 时运行
dexopt,将.dex文件优化成.odex文件,存储在设备的/data/dalvik-cache/或/system/app/目录下。
- 在 Dalvik 虚拟机上,系统会在安装 APK 时运行
- 共享库功能:
- 优化后的
.odex文件可以作为共享库,减少不同应用中相同类加载的冗余。
- 优化后的
** 在 ART 虚拟机时代**
- 在 ART 上,系统不再直接生成
.odex文件,而是生成更高效的.oat文件。 - 优化流程(AOT 编译):
- APK 安装时,系统将
.dex文件编译为本地机器码,生成.oat文件。 - 优化后的
.oat文件与原始 APK 一起存储。
- APK 安装时,系统将
如何查看 ODEX 文件
** 手动查看**
使用 adb shell查看设备上的 ODEX 文件:
1
ls /data/dalvik-cache/
查看
/system/app/目录下的系统应用是否包含.odex文件。
** 反编译工具**
使用反编译工具(如 Baksmali 或 JADX):
通过 Baksmali 将
.odex文件反编译为.smali文件。示例:
1
java -jar baksmali.jar -x MyApp.odex
dex、odex、oat、ydex文件区别
dex文件:先将java文件编译成class文件,然后用Android将所有的class文件打包,形成Dalvik运行的可执行文件–dex。(Dalvik字节码)
odex文件:优化过的dex文件,Apk在安装时会进行验证和优化,通过dexopt生成odex文件,加快Apk的响应时间。在Android 5之后,.odex就不再是odex文件了,而是oat文件,文件头是”ELF”。
oat文件:Android私有ELF文件格式,由dex2oat处理生成,包含(原dex文件+dex翻译的本地机器指令),是ART虚拟机便用的文件,可以直接加载
vdex文件:Android8.0引l入,包含APk的未压缩DEx代码,以及一些旨在加快验证速度的元数据,其目的主要是为了跳过verified流程,减少dex2oat执行时间。
ELF
ELF文件的三种文件类型:
可重定位目标文件:包含二进制代码和数据,其形式可以和其他目标文件进行合并,创建一个可执行目标文件。比如linux下的.o文件
可执行目标文件:包含二进制代码和数据,可直接被加载器加载执行。 比如/bin/sh文件
共享目标文件:可被动态的加载和链接 比如.so文件
Core Dump File:进程意外终止时可以产生的文件,存储着该进程的内存空间中的内容等信息 比如core dump文件
elf的结构:
•ELF头部(ELF Header),用来描述整个文件的组织。节区部分包含链接视图的大量信息:指令、数据、符号表、重定位信息等。
•程序头部表(Program Header Table),如果存在的话,会告诉系统如何创建进程映像。用来构造进程映像的目标文件必须具有程序头部表,可重定位文件不需要这个表。
•节区头部表(Section Header Table),包含了描述文件节区的信息,每个节区在表中都有一项,每一项给出诸如节区名称、节区大小这类信息。用于链接的目标文件必须包含节区头部表,其他目标文件可以有,也可以没有这个表。
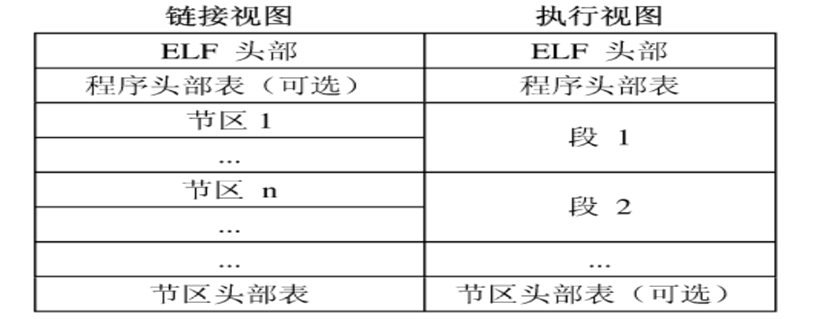
开头的ELF Header描述了体系结构和操作系统等基本信息并指出Section Header Table和Program Header Table在文件中的什么位置,
Program Header Table中保存了所有Segment的描述信息;在汇编和链接过程中没有用到,所以是可有可无的
Section Header Table中保存了所有Section的描述信息;Section Header Table在加载过程中没有用到,所以是可有可无的
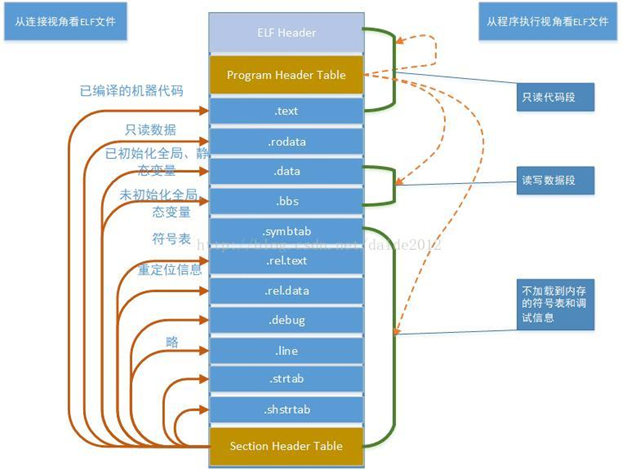
readelf这个命令来查看文件的结构
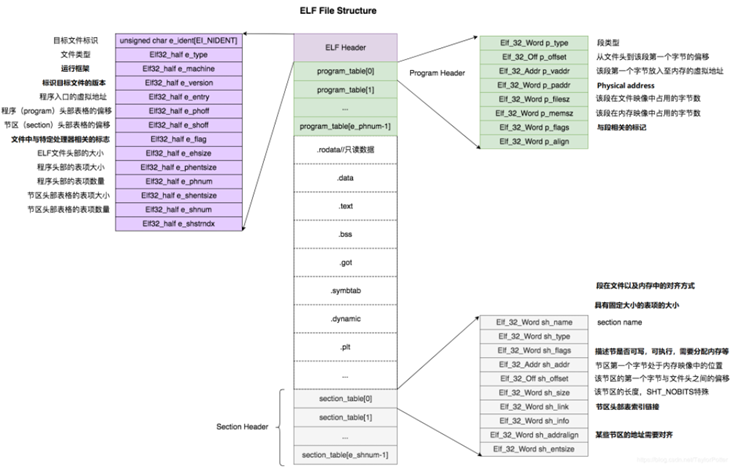
ELF Header
1 | //https://github.com/bminor/glibc/blob/glibc-2.27/elf/elf.h |
| 字段 | 类型 | 描述 |
|---|---|---|
| e_ident | unsigned char[EI_NIDENT] |
ELF 文件的标识信息数组(16 字节),包括魔术数字、文件类型、版本等信息。 |
| e_type | Elf32_Half |
表示文件类型,常见的值包括:ET_EXEC(可执行文件)、ET_DYN(共享库)、ET_REL(目标文件)。 |
| e_machine | Elf32_Half |
表示文件适用的机器体系结构,如 EM_386(x86)或 EM_X86_64(x86_64)。 |
| e_version | Elf32_Word |
文件版本,通常为 EV_CURRENT。 |
| e_entry | Elf32_Addr |
程序入口点的虚拟地址,程序执行的起始位置。 |
| e_phoff | Elf32_Off |
程序头表的偏移量,指向程序头表(包含各个段的相关信息)。 |
| e_shoff | Elf32_Off |
节头表的偏移量,指向节头表(包含文件的节的相关信息,如 .text、.data)。 |
| e_flags | Elf32_Word |
处理器特定的标志,表示如何处理该 ELF 文件。 |
| e_ehsize | Elf32_Half |
ELF 文件头的大小(以字节为单位)。 |
| e_phentsize | Elf32_Half |
程序头表中每个条目的大小(以字节为单位)。 |
| e_phnum | Elf32_Half |
程序头表条目的数量,表示该 ELF 文件中包含多少个段。 |
| e_shentsize | Elf32_Half |
节头表中每个条目的大小(以字节为单位)。 |
| e_shnum | Elf32_Half |
节头表条目的数量,表示该 ELF 文件中的节的数量。 |
| e_shstrndx | Elf32_Half |
节头字符串表的索引,指向包含节名的字符串表。 |
Section Header
1 | typedef struct |
字段分析表格:
| 字段名称 | 类型 | 大小(字节) | 描述 | 示例/备注 |
|---|---|---|---|---|
sh_name |
Elf32_Word |
4 | 段名称在字符串表(.shstrtab)中的索引。若为 0,表示无名称。 |
.text 段的名称索引可能为 0x0A(指向字符串表中的偏移)。 |
sh_type |
Elf32_Word |
4 | 段的类型,定义段的用途和内容格式。常见值见备注。 | SHT_PROGBITS (1):程序数据(如代码或初始化数据)。 SHT_SYMTAB (2):符号表。 |
sh_flags |
Elf32_Word |
4 | 段的属性标志位(可组合使用),定义段的权限或行为。 | SHF_WRITE (0x1):段可写。 SHF_ALLOC (0x2):段在内存中加载。 SHF_EXECINSTR (0x4):段包含可执行指令。 |
sh_addr |
Elf32_Addr |
4 | 段在进程虚拟地址空间中的起始地址。若为 0,表示该段不加载到内存(如调试信息)。 |
.text 段可能为 0x8048000(可执行代码的加载地址)。 |
sh_offset |
Elf32_Off |
4 | 段在文件中的偏移量(从文件开头计算)。 | 若为 0x200,表示段数据从文件第 512 字节开始。 |
sh_size |
Elf32_Word |
4 | 段的大小(字节)。若段包含固定大小的表(如符号表),则为表的总字节数。 | .text 段大小可能为 0x500(1280 字节的代码)。 |
sh_link |
Elf32_Word |
4 | 指向另一个段的索引,具体含义取决于 sh_type。 |
符号表段(SHT_SYMTAB)的 sh_link 指向字符串表段(.strtab)的索引。 |
sh_info |
Elf32_Word |
4 | 附加信息,具体含义取决于 sh_type。 |
符号表段(SHT_SYMTAB)的 sh_info 表示最后一个局部符号(st_local)的索引 + 1。 |
sh_addralign |
Elf32_Word |
4 | 段的内存对齐要求(必须是 2 的幂)。若为 0 或 1,表示无对齐要求。 |
.text 段可能对齐到 0x10(16 字节对齐)。 |
sh_entsize |
Elf32_Word |
4 | 如果段包含固定大小的表(如符号表),表示表中每个条目的大小;否则为 0。 |
符号表(SHT_SYMTAB)的 sh_entsize 为 0x10(每个符号条目占 16 字节)。 |
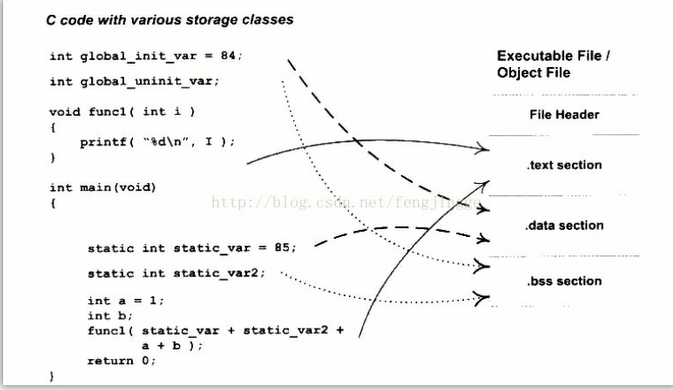
ELF sections

ELF Sections
| 节名 | 类型 | 描述 |
|---|---|---|
.text |
可执行代码 | 包含程序的机器指令,程序的实际执行代码。通常是只读且可执行的。 |
.data |
数据段 | 包含程序需要的已初始化数据,通常是可读可写的。 |
.bss |
未初始化数据段 | 包含未初始化的数据,程序启动时会被清零,通常不占用文件空间,只有内存中有分配空间。 |
.rodata |
只读数据段 | 包含程序的常量数据,如字符串字面量等。通常是只读且不可写的。 |
.symtab |
符号表 | 存储程序中定义的符号信息,符号包括函数、变量等。用于符号解析。 |
.strtab |
字符串表 | 存储符号表中所有符号的名称,符号表条目包含指向这个字符串表的索引。 |
.shstrtab |
节头字符串表 | 存储所有节的名称,是节头中每个节名称的字符串表。 |
.text.hot |
热代码段 | 存储频繁执行的代码,常用于性能优化的场景,分开存放。 |
.ctors |
构造函数表 | 包含程序执行前需要调用的构造函数地址。 |
.dtors |
析构函数表 | 包含程序结束时需要调用的析构函数地址。 |
.note |
注释信息 | 存储程序的注释信息,如编译器版本、操作系统版本等元数据。 |
.dynamic |
动态链接表 | 存储程序的动态链接信息,包含库的依赖和符号解析信息。 |
.rel / .rela |
重定位表 | 包含符号地址修改的必要信息,rela 比 rel 多一个附加信息字段。 |
.comment |
编译信息 | 存储编译时的注释信息,通常由编译器生成。 |
.debug |
调试信息 | 包含源代码、变量、函数等信息,用于调试工具对程序的调试和符号解析。 |
.plt |
程序链接表 | 存储动态链接的函数调用指针,通常用于延迟加载和动态链接函数调用。 |
.got |
全局偏移表 | 存储全局变量和函数的地址,是动态链接过程中的重要数据结构。 |