


LLVM简介
LLVM(Low Level Virtual Machine)是一个开源的编译器基础架构,它最初是作为一种中间表示(IR)语言和一个优化框架设计的,目标是支持高效的编译和生成可执行代码。LLVM并不只是一种编译器,而是一个编译工具链,旨在为现代编程语言提供高度可重用的编译工具。如果需要支持一种新的编程语言,那么只需要在LLVM中实现一个新的前端即可。如果需要支持一种新的硬件设备,那么只需要在LLVM中实现一个新的后端即可。无论是怎样的前端后端,代码进行编译优化等操作都会借助IR代码来进行。
LLVM的核心目标是提供一套可移植、模块化、可扩展的编译工具链,它能够支持多种硬件架构并进行代码优化。
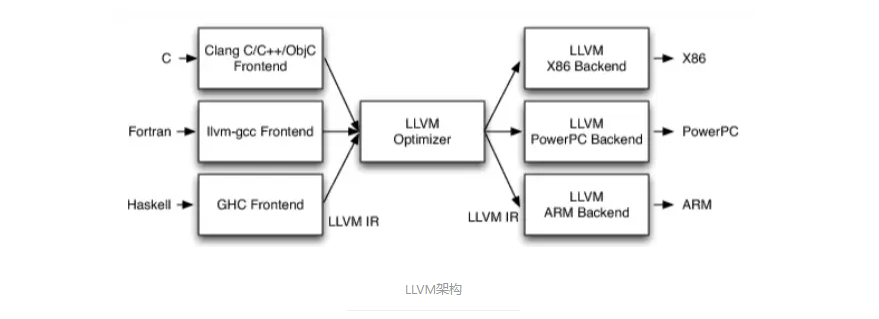
组成:
LLVM前端:
前端负责将源代码转换为LLVM IR。LLVM本身并不提供这些语言的前端,而是通过外部项目来提供。例如,
clang是一个基于LLVM的C/C++/Objective-C前端,它会将C语言源代码转换成LLVM IR。交付给优化器。LLVM支持两种前端:clang和基于GNU编译器集合解析器的前端。LLVM优化器(LLVM Optimizer):
优化器负责删除IR代码中的冗余代码和死代码、简化控制流图等。之后将结果传送给后端。优化的目的是提高代码的效率,减少资源消耗。LLVM提供了大量的优化算法。
LLVM后端:
根据目标架构生成高效的汇编代码。后端将LLVM IR转化为目标机器代码。后端的任务包括寄存器分配、指令选择、目标特定优化等。
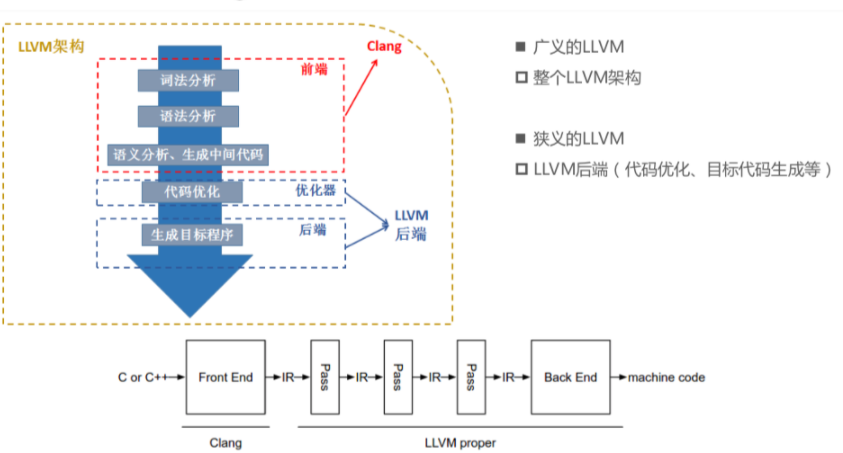
LLVM的运行流程分为以下主要阶段:
- 前端(Front-End):将源代码(如C/C++/Rust等)通过clang转换为LLVM IR。
- 中端(Middle-End):优化和分析LLVM IR。(主要使用的是Pass)
- 后端(Back-End):将优化后的LLVM IR生成目标机器代码。
clang
Clang 是 LLVM 项目中的 C/C++/Objective-C 编译器前端,提供了完整的编译器功能,包括从源代码到目标代码的整个流程。它的核心任务是将高级语言源代码解析为 LLVM 中间表示(IR),并最终交给 LLVM 的中间端和后端完成优化和代码生成。
与gcc相比:
1.编译速度快:在某些平台上,Clang的编译速度显著的快过GCC(Debug模式下编译OC速度比GGC快3倍)
2.占用内存小:Clang生成的AST所占用的内存是GCC的五分之一左右
3.模块化设计:Clang采用基于库的模块化设计,易于 IDE 集成及其他用途的重用
4.诊断信息可读性强:在编译过程中,Clang 创建并保留了大量详细的元数据 (metadata),有利于调试和错误 报告
5.设计清晰简单,容易理解,易于扩展增强
Clang 的运行流程大致可以分为几个主要步骤:预处理(Preprocessing)、词法分析(Lexical Analysis)、语法分析(Parsing)、语义分析(Semantic Analysis)、代码生成(Code Generation) 以及 优化(Optimization)
词法分析
Clang 的词法分析是编译过程中的第一个重要步骤,负责将源代码文本转换成一系列的标记(tokens)。这些标记将为后续的语法分析和语义分析提供基础。Clang 的词法分析是基于 C++ 编写的,它的设计非常模块化,并与预处理器(Preprocessor)紧密协作,支持复杂的编译需求(如宏展开、条件编译等)。在 Clang 中,词法分析器的核心部分由 Lexer 类实现。
词法分析的主要目标是:
- 生成标记(Tokens):将源代码分解成易于分析的基本单元。
- 丢弃无用字符:如空格、注释等。
- 错误检测:如非法字符或语法错误的报告。
1 | clang -fmodules -E -Xclang -dump-tokens main.m |
示例:
1 | int main() { |
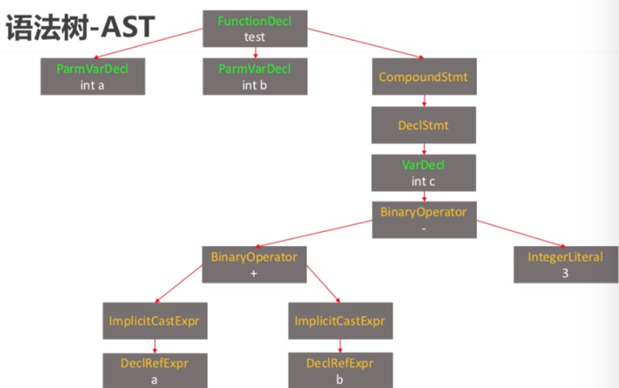
语法分析——生成语法树(AST)
Clang 的语法分析阶段是编译过程中的关键步骤之一,负责将词法分析(Lexer)阶段生成的标记(tokens)转换成 抽象语法树(Abstract Syntax Tree,AST)。AST 是源代码的树形表示,其中每个节点代表程序中的一个语法结构(如声明、表达式、语句等)。AST 结构相对较高层次,便于进行语义分析、优化和后续的代码生成。
在 Clang 中,Parser 类负责执行语法分析,它基于语言的文法规则将标记(tokens)构建成抽象语法树。
Parser 的工作流程
- 标记读取:每次 Parser 读取一个标记(Token)并决定该标记对应的语法结构。
- 递归解析:Parser 会递归调用相应的语法规则方法,构建子树并连接到父节点。
- 错误报告:如果在语法分析过程中遇到不符合文法的标记,Parser 会生成错误报告。
1 | clang -fmodules -fsyntax-only -Xclang -ast-dump main.m |
1 | FunctionDecl 0x55615b7f4400 <input.c:1:1, line:3:1> line:1:1 add 'int' ParmVarDecl 0x55615b7f3b00 <col:7, col:8> 'int' a |
语义分析,生成中间码IR
通过ASTConsumer函数换成IR代码
Clang 的 语义分析(Semantic Analysis)是编译过程中的一个重要阶段,负责确保程序的语法结构不仅符合语言的文法规则,而且符合语言的语义规则。在这一阶段,编译器会检查程序中的类型、作用域、符号定义等方面的错误,并生成符号表以支持后续的代码生成和优化。Clang 的语义分析是基于 AST 的遍历实现的。
语义分析的目标是确保代码的含义(而非语法)是正确的,例如:
- 类型检查:确保变量、表达式和函数调用的类型匹配。
- 符号查找:确保所有使用的变量和函数在作用域内已经声明。
- 作用域管理:确保变量和函数在适当的作用域内被使用。
- 常量折叠:对常量表达式进行计算并简化代码。
IR
不同的前端后端使用统一的中间代码LLVM Intermediate Representation (LLVM IR) 。它是LLVM优化和代码生成的基础。LLVM IR设计为目标无关的中间层,支持多种语言和架构。
特点:
- 三种表示形式:
文本格式(.ll):人类可读的纯文本表示,便于调试和分析。text
$ clang -S -emit-llvm main.m1
2
3- **二进制格式(.bc)**:高效的存储和传输格式,用于编译器内部。bitcode
- ```shell
$ clang -c -emit-llvm main.m内存表示:编译器运行时使用的内存结构,由LLVM API操控。memory
- 面向静态单赋值(SSA)形式:
- LLVM IR使用SSA形式,这意味着每个变量在其作用域内只能被赋值一次。
- SSA形式使数据流分析和优化(如常量传播、冗余消除)更加高效。
LLVM IR是由基本块(Basic Block)组成的,基本块是一系列顺序执行的指令,程序的控制流通过基本块间的跳转来实现。示例:
IR基本语法
注释以分号;开头
全局标识符以@开头,局部标识符以%开头
alloca,在当前函数栈帧中分配内存
i32,32bit,4个字节的意思
align,内存对齐
store,写入数据
load,读取数据
1 |
|
Clang:
- Clang编译器将C/C++/Objective-C代码转换为LLVM IR。
LLVM优化工具:
opt工具用于对LLVM IR进行优化。
IR解释器:
lli可直接运行LLVM IR代码。
分析工具:
- 可以使用
llvm-dis将二进制IR转换为文本格式,或llvm-as将文本IR转为二进制。
将C语言代码转换成LLVM IR
1 | clang -emit-llvm -S hello.c -o hello.ll |
pass
https://llvm.org/docs/WritingAnLLVMPass.html#quick-start-writing-hello-world
在 LLVM 中,Pass 是对中间表示(IR)进行分析和优化的基本单元。Pass 通常由编译器的不同阶段使用,以提高生成代码的效率、执行速度、空间利用率等。LLVM 的 Pass 架构是模块化和可定制的,每个 Pass 关注 IR 的特定方面,如优化、分析、验证等。
Pass 可以分为以下几类:
- 分析 Pass:分析 IR 中的数据流、控制流、依赖关系等,通常不会改变 IR。
- 转换 Pass(Optimization Pass):修改 IR,通常是为了进行优化,提高程序的性能。
- 验证 Pass:确保 IR 符合 LLVM 的内部约定和规范,防止错误的 IR 影响后续处理。
- 后端 Pass:在将 IR 转换为机器代码之前执行,通常包括目标特定的优化。
Pass 的结构
每个 Pass 都是一个类,并继承自 llvm::Pass 或其子类。在 Pass 类中,你会看到以下结构:
- 初始化:Pass 通常在创建时会进行初始化,设置相关的标志或配置。
- 运行:Pass 的核心逻辑通常在
runOnFunction、runOnModule或runOnBasicBlock方法中实现。这些方法定义了 Pass 在不同级别的操作。 - 结束:Pass 完成后,LLVM 会处理 Pass 的结果,更新 IR 或将 IR 传递给下一个 Pass。
如何使用和自定义 Pass
** 使用内置 Pass**
LLVM 提供了许多内置的 Pass,用户可以通过 opt 工具或者在程序中手动插入这些 Pass 来应用优化。
使用
opt工具运行 Pass:1
opt -O2 input.bc -o output.bc # 使用优化 Pass
其中,
-O2是优化级别,input.bc是输入的 LLVM IR 文件,output.bc是输出的优化后的 IR 文件。通过编程接口使用 Pass: 如果你在开发自己的应用程序,可以使用 LLVM API 来加载模块并应用 Pass。
1
2
3
4llvm::PassManager PM;
PM.add(llvm::createDeadCodeEliminationPass()); // 添加 DCE Pass
PM.add(llvm::createFunctionInliningPass()); // 添加内联 Pass
PM.run(M); // M 是一个 llvm::Module 对象
自定义 Pass
如果你需要实现自己的 Pass,可以通过继承 llvm::FunctionPass、llvm::ModulePass 等类来定义一个新的 Pass。例如,下面是一个简单的函数级 Pass 示例:
1 |
|
runOnFunction方法中可以编写对 IR 的修改逻辑。ModulePass也类似,只是它作用于整个模块。RegisterPass宏将 Pass 注册到 LLVM 中,以便可以通过opt或其他工具使用。
Pass 管理系统
LLVM 提供了 PassManager 类用于管理和运行一组 Pass。PassManager 会负责执行每个 Pass,自动处理 Pass 之间的依赖关系,以及控制 Pass 的执行顺序。
- FunctionPassManager:用于管理和运行函数级别的 Pass。
- ModulePassManager:用于管理和运行模块级别的 Pass。
Pass 的优化级别
LLVM 提供了多种优化级别(-O1、-O2、-O3 等),每个级别对应一组优化 Pass。更高的优化级别通常会启用更多的优化 Pass,但可能会增加编译时间。例如,-O2 启用的 Pass 包括常量传播、死代码消除等,而 -O3 还会启用更高级的优化,如循环展开和向量化。
编译
选择14.0.0版本
依赖参考安卓的一键安装https://source.android.com/docs/setup/build/initializing?hl=zh-cn
1 | sudo apt install ninja-build |
安装clion
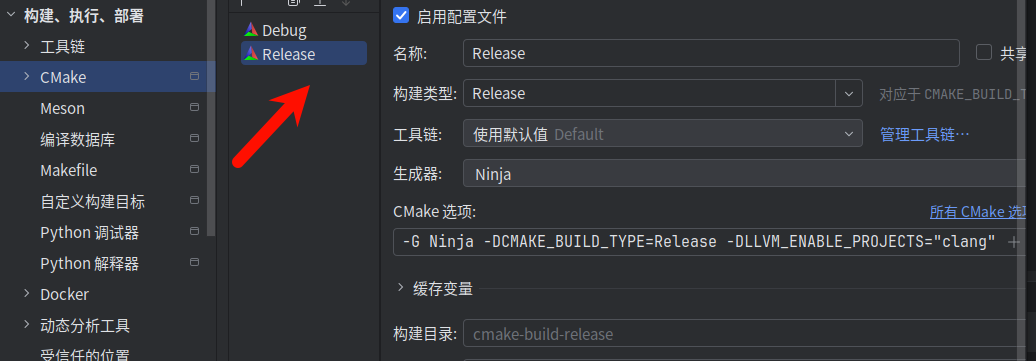
然后使用Clion打开llvm目录下的CmakeLists.txt
进入settings,然后CMake里点击+会添加Release版本,我们需要在CMake 选项里填上我们之前编译时用的命令
然后多了两个目录:
然后进入这两个目录进行编译(时间有点久)
1 | sudo ninja -j8 |
clang编译c源码
设置环境变量
1 | export PATH=~/tools/llvm/llvm-14.0.0/llvm/cmake-build-release/bin:$PATH |
编译
1 | clang main.c -o hello_clang |

调试Clang
找到llvm/llvm-14.0.0/clang/tools/driver下driver.cpp的main函数位置下个断点
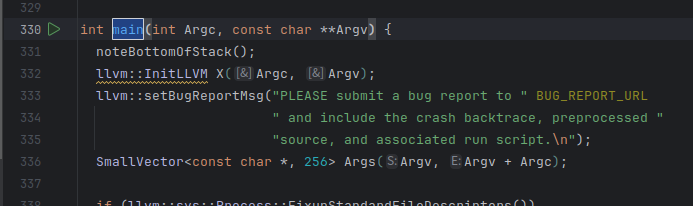
编译选择clang
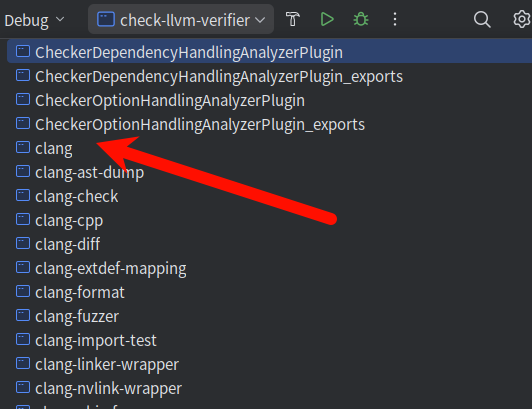
设置运行参数
目录文件 -o 生成文件
/home/cruve/CLionProjects/untitled/hello.c -o /home/cruve/CLionProjects/untitled/test
然后运行调试。(前面没有编译debug模式,clion编译)

工具
https://llvm.org/docs/GettingStarted.html#llvm-tools
| 工具名称 | 功能描述 | 用途 |
|---|---|---|
| bugpoint | 将给定的测试用例缩小到最小的通过和/或仍然导致问题的指令数量,无论是崩溃还是错误编译 | 调试优化过程或代码生成后端 |
| llc | 将 LLVM IR 转换为特定架构的汇编代码 | 将 LLVM IR 生成汇编代码 |
| llvm-as | 将 LLVM IR 文本转换为二进制格式 | 将 LLVM IR 源代码编译为二进制格式 |
| llvm-dis | 将 LLVM 二进制文件转换为文本格式 | 将二进制 LLVM IR 文件转换为文本格式 |
| opt | LLVM IR 优化工具 | 执行各种类型的 LLVM IR 优化 |
| llvm-link | 链接多个 LLVM IR 文件 | 合并多个 .bc 文件 |
| llvm-ar | LLVM 归档工具 | 创建、修改或提取 .a 静态库文件 |
| llvm-nm | 显示目标文件的符号信息 | 查看目标文件中的符号表 |
| llvm-objdump | 反汇编目标文件并显示其内容 | 分析汇编代码、符号表,帮助调试 |
| llvm-profdata | 处理性能分析数据 | 生成和合并程序的覆盖率数据 |
| llvm-cov | 提供代码覆盖率信息 | 生成覆盖率报告,帮助测试和优化程序 |
| lli | LLVM JIT(即时编译器)解释器 | 执行 LLVM IR 代码 |
| clang-tidy | 静态分析工具,检查 C++ 代码中的潜在错误和风格问题 | 检查代码质量、潜在错误、风格问题 |
| clang-format | 自动格式化 C/C++ 等语言的源代码 | 自动格式化源代码,确保代码风格一致 |
| FileCheck | 用于验证输出文件中是否包含预期文本 | 用于验证编译器的输出或 IR 是否符合预期 |
| llvm-debug | 用于调试目标文件的工具 | 调试 LLVM 编译的目标文件 |
自定义的PASS
Writing an LLVM Pass (legacy PM version) — LLVM 20.0.0git documentation
看一下llvm自带的pass示例(llvm/lib/Transforms/hello/hello.cpp)
每当执行一个函数时就输出hello和函数名。
通过 errs() << "Hello: "; 打印 "Hello: ",然后通过 F.getName() 获取当前函数的名称并输出,write_escaped 用于避免输出过程中发生特殊字符错误。
1 | namespace { |
编译好的so文件在
1 | llvm-14.0.0/llvm/cmake-build-release/lib |
使用方法
1 | opt -load /home/cruve/tools/llvm/llvm-14.0.0/llvm/cmake-build-release/lib/LLVMHello.so -help |grep hello |

我们在Trasform的目录下新创一个目录:NewPass
该文件夹同样创建NewPass.cpp、CMakeLists.txt。NewPass.exports(为空)
在NewPass的CMakeLists.txt中参照hello的cmakelist修改下部分
1 | set(LLVM_EXPORTED_SYMBOL_FILE ${CMAKE_CURRENT_SOURCE_DIR}/NewPass.exports) |
然后在上级目录(Transforms)下的CMakeLists.txt中,添加新创建的目录:
1 | add_subdirectory(NewPass) |
在NewPass.cpp
1 |
|
然后先重新加载cmake

然后在目录下 ninja LLVMNewPass

然后进入我们之前编译好的hello.c文件目录下
1 | opt -load /home/cruve/tools/llvm/llvm-14.0.0/llvm/cmake-build-release/lib/LLVMNewPass.so -NewPass -enable-new-pm=0 hello.ll -o hello.bc |

完毕!