去指令替换混淆 LLVM 提供了一些优化 Pass,可以用于简化和优化编译后的 IR(中间表示)代码,去除无意义的混淆指令。尤其是使用 llvm-dis 反汇编指令后,我们可以通过 opt 工具结合 -O3 优化级别来简化程序。此方法的核心思想是利用 LLVM 编译工具链中内置的优化技术,自动剖析和去除冗余的指令替换。
或者使用Miasm框架进行匹配,然后优化处理即可。Miasm 是一个专注于逆向工程的框架,它允许研究人员进行二进制分析、控制流恢复和混淆去除。Miasm 通过模拟二进制代码的执行,自动化地识别程序中的混淆模式,并通过去除冗余指令来简化程序。它尤其适用于静态分析与指令替换的混淆。
反字符串加密 字符串加密的的常规解决方式:
(1)特征搜索
思路:
在很多使用字符串加密的二进制中,会存在一个解密函数,例如 datadiv_decode 或其他命名类似的函数。这些解密函数通常通过某种算法(如异或、加法等)将加密的字符串还原成明文。
通过在二进制中搜索特定的解密函数,可以快速定位到解密的逻辑。
(2)init_array中解密
在某些情况下,程序可能会在 init_array 中进行字符串解密。init_array 是在程序启动时执行的代码区域,通常用于初始化操作。在 OLLVM 混淆中,解密可能发生在此区域中。
思路:
init_array 中的解密操作在程序启动时执行,因此通过模拟程序启动过程,可以将解密后的字符串提取出来。可以通过动态分析工具或模拟执行来查看该区域的解密过程,并获取解密后的字符串。
(3)jni_onload解密
jni_onload 是 JNI(Java Native Interface)中的一个特殊函数,通常会在 JNI 库加载时被调用。在 OLLVM 中,字符串解密操作有时会放在 jni_onload 中进行。
思路:
在 JNI 库加载时,解密操作可能会在 jni_onload 函数中执行,通常是为了准备一些加密数据供 Java 层使用。
可以通过 hook jni_onload 函数,或者使用 Unicorn 模拟执行,从中获取解密后的字符串。
反虚假控制流 虚假控制流去除的思路一般为除去不可达块和不透明谓词。但是难点在于不透明谓词,现在不透明谓词的研究不断发展,有永真/永假型不透明谓词,也有可真可假型不透明谓词。当然针对复杂的虚假控制流,在反混淆过程中还需要考虑死循环等问题
不透明谓词:
1 2 永真/假型:插入的后续基本块中必有一个不被执行 可真可假型:插入的两个后继基本块的语义应相同
针对简单的控制流混淆,去不透明谓词的思想主要是:
1 2 3 (1)不直接处理不透明谓词,通过让不透明谓词的变量地址可读,则IDA便可以优化 (2)直接将不透明谓词赋值为0或者将不透明谓词中变量x,y赋值为0 (3)编译器优化去干掉不透明谓词
不可达块:
不可达块是指控制流永远无法到达的基本块,一般我们可以使用符号执行或模拟执行来除去不可达基本块
idapython脚本;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import ida_xrefimport ida_idaapifrom ida_bytes import get_bytes, patch_bytesfrom ida_segment import get_segm_by_namedef do_patch (ea ): """ 检查并替换不透明谓词的 mov 操作,将其替换为 mov 寄存器, 0 """ opcode = get_bytes(ea, 1 ) if opcode == b"\x8B" : reg = (ord (get_bytes(ea + 1 , 1 )) & 0b00111000 ) >> 3 patch_bytes(ea, (0xB8 + reg).to_bytes(1 , 'little' ) + b'\x00\x00\x00\x00\x90' ) else : print (f"Unsupported instruction at {hex (ea)} " ) def get_bss_segment (): """ 获取 BSS 段的地址范围 """ seg = get_segm_by_name('.bss' ) if seg is None : print ("BSS segment not found." ) return None , None return seg.start_ea, seg.end_ea def patch_control_flow (start, end ): """ 对指定的地址范围内的虚假控制流进行修复 """ for addr in range (start, end, 4 ): ref = ida_xref.get_first_dref_to(addr) print (f"Processing references for address {hex (addr)} " .center(40 , '-' )) while ref != ida_idaapi.BADADDR: print (f"Patch reference at {hex (ref)} " ) do_patch(ref) ref = ida_xref.get_next_dref_to(addr, ref) print ('-' * 40 ) def main (): start, end = get_bss_segment() if start is None or end is None : return patch_control_flow(start, end) if __name__ == "__main__" : main()
反控制流平坦化
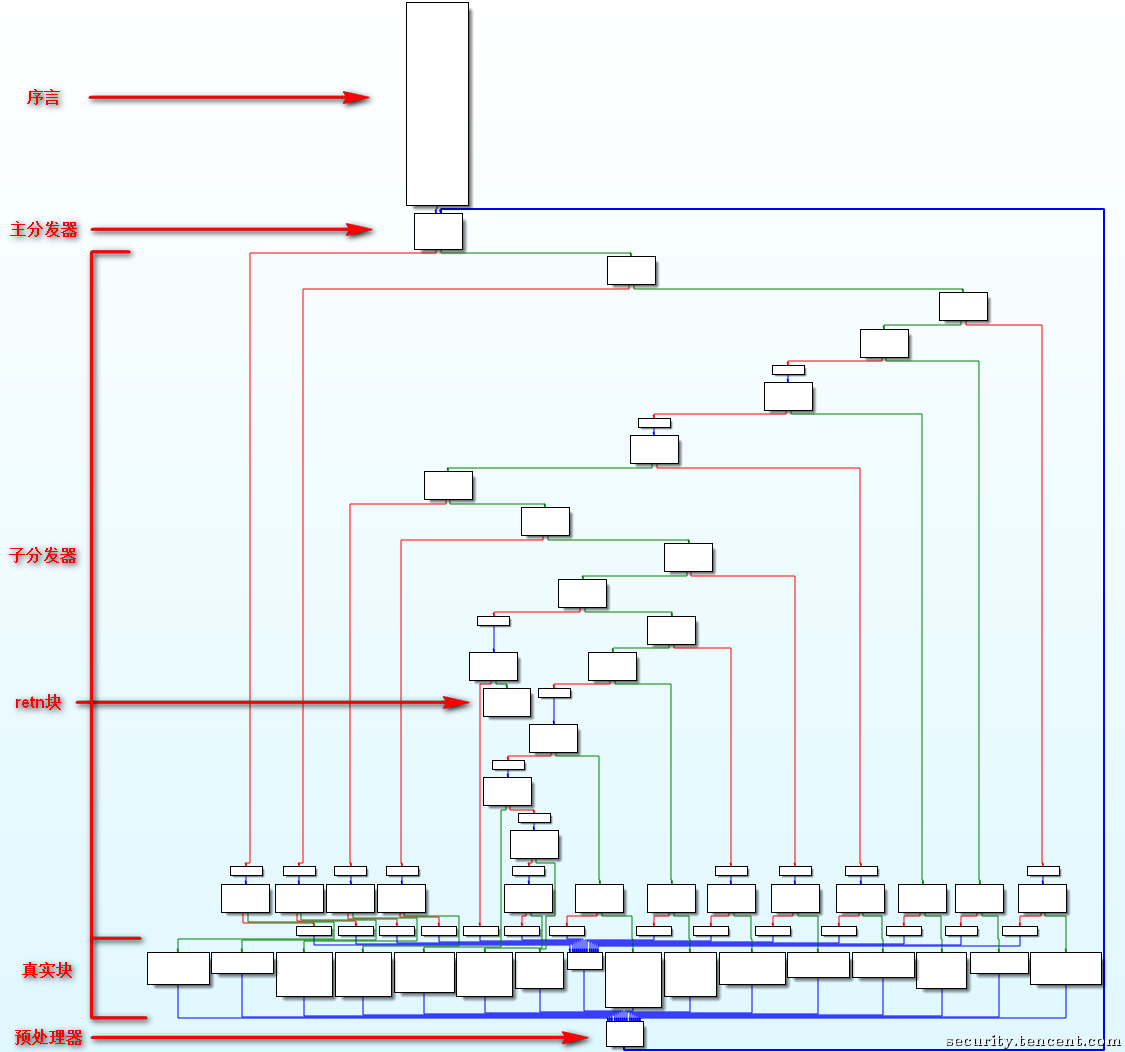
其代码的真实逻辑在:序言块、真实块(相关块)、retn块中。
反控制流平坦化的核心在于准确区分真实块与分发器,并恢复真实块的顺序。通过特征匹配与动态执行相结合,可以高效完成大多数情况的去混淆工作。修补过程中优先使用简单的跳转逻辑,必要时对函数进行整体重构,以最大限度恢复代码的可读性和逻辑完整性。
一般通用的反控制流平坦化思路:
(1)先保存所有的基本块
保存所有的基本块 控制流平坦化将代码逻辑碎片化,因此反混淆的首要任务是提取所有的基本块:
基本原理: 控制流平坦化重构执行流为三类链:
入口链(Prologue Chain): 原始函数的入口到主分发器的路径。循环链(Loop Chain): 主分发器之间的循环跳转路径。返回链(Return Chain): 主分发器到函数结束的路径。
操作: 通过静态分析工具(如 IDA Pro)或动态分析工具(如调试器)提取目标函数的所有基本块,并初步分类。重点关注分发器(Dispatcher)的识别(详见第 2 步)。
区分真实块和分发器 分发器是控制流平坦化的核心逻辑节点,其作用是引导流程跳转到下一个基本块。区分真实块与分发器的关键如下:
分发器的特征:
引用次数较高: 分发器是执行链的核心节点,其引用次数远高于其他基本块。结构固定: 分发器通常包含跳转逻辑,如 switch-case 或复杂的 if-else。
真实块的特征:
内存操作: 包含内存访问指令(如 ldr, str)。函数调用: 出现 bl 或 blx 指令。确定性跳转: 出现明确的条件跳转指令(如 beq, bne)。
方法:
遍历函数的所有基本块,统计每个块的引用次数。
通过特征匹配(如常用指令模式)识别真实块和分发器。
连接真实块的顺序 重建真实块的顺序是反控制流平坦化的核心
静态方法:
使用 IDA Pro 的 Trace 功能获取执行路径。
编写 IDAPython 脚本解析每个基本块的连接关系。
判断分支条件,重建代码逻辑。
动态方法:
使用符号执行工具(如 angr)模拟执行代码。
跟踪每条路径的执行结果。
遇到复杂分支时,结合人工分析调整路径。
特殊情况处理:
对于真实块包含双路径(movwne/movtne r1)的情况,需要分别处理两条路径并连接至对应的真实块。
编写patch 修补代码是反混淆的最后一步,以下是两种主要方法:
基于angr的脚本学习: cq674350529/deflat: use angr to deobfuscation
deflt.py get_relevant_nop_nodes 函数从一个超级控制流图(supergraph)中提取:
相关节点(relevant_nodes):
与主要分发节点(pre_dispatcher_node)相连并且逻辑上有用的节点。
NOP 节点(nop_nodes):
1 2 3 4 5 6 7 8 9 10 11 12 13 def get_relevant_nop_nodes (supergraph, pre_dispatcher_node, prologue_node, retn_node ): relevant_nodes = [] nop_nodes = [] for node in supergraph.nodes(): if supergraph.has_edge(node, pre_dispatcher_node) and node.size > 8 : relevant_nodes.append(node) continue if node.addr in (prologue_node.addr, retn_node.addr, pre_dispatcher_node.addr): continue nop_nodes.append(node) return relevant_nodes, nop_nodes
symbolic_execution 函数利用 angr 库进行符号执行(Symbolic Execution),分析程序的动态行为,目标是:
从给定起始地址(start_addr)开始,模拟执行程序的控制流。
判断当前路径是否到达指定的相关基本块地址列表(relevant_block_addrs)。
通过设置断点和hook,控制程序执行过程,并根据需求修改状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def symbolic_execution (project, relevant_block_addrs, start_addr, hook_addrs=None , modify_value=None , inspect=False ): def retn_procedure (state ): ip = state.solver.eval (state.regs.ip) project.unhook(ip) return def statement_inspect (state ): expressions = list (state.scratch.irsb.statements[state.inspect.statement].expressions) if len (expressions) != 0 and isinstance (expressions[0 ], pyvex.expr.ITE): state.scratch.temps[expressions[0 ].cond.tmp] = modify_value state.inspect._breakpoints['statement' ] = [] if hook_addrs is not None : skip_length = 4 if project.arch.name in ARCH_X86: skip_length = 5 for hook_addr in hook_addrs: project.hook(hook_addr, retn_procedure, length=skip_length) state = project.factory.blank_state(addr=start_addr, remove_options={angr.sim_options.LAZY_SOLVES}) if inspect: state.inspect.b('statement' , when=angr.state_plugins.inspect.BP_BEFORE, action=statement_inspect) sm = project.factory.simulation_manager(state) sm.step() while len (sm.active) > 0 : for active_state in sm.active: if active_state.addr in relevant_block_addrs: return active_state.addr sm.step() return None
创建 angr 项目对象,加载二进制文件。
使用 CFGFast 构建快速控制流图(CFG),启用 normalize 以避免基本块重叠。
1 2 3 4 project = angr.Project(filename, load_options={'auto_load_libs' : False }) cfg = project.analyses.CFGFast(normalize=True , force_complete_scan=False ) base_addr = project.loader.main_object.mapped_base >> 12 << 12
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 target_function = cfg.functions.get(start) if target_function is None : target_function = cfg.kb.functions.get_by_addr(base_addr + start) supergraph = am_graph.to_supergraph(target_function.transition_graph) prologue_node = None for node in supergraph.nodes(): if supergraph.in_degree(node) == 0 : prologue_node = node if supergraph.out_degree(node) == 0 and len (node.out_branches) == 0 : retn_node = node if prologue_node is None or prologue_node.addr not in [start, base_addr + start]: print ("Something must be wrong..." ) sys.exit(-1 ) main_dispatcher_node = list (supergraph.successors(prologue_node))[0 ] for node in supergraph.predecessors(main_dispatcher_node): if node.addr != prologue_node.addr: pre_dispatcher_node = node break relevant_nodes, nop_nodes = get_relevant_nop_nodes(supergraph, pre_dispatcher_node, prologue_node, retn_node)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 relevants = relevant_nodes relevants.append(prologue_node) relevants_without_retn = list (relevants) relevants.append(retn_node) relevant_block_addrs.extend([prologue_node.addr, retn_node.addr]) flow = defaultdict(list ) patch_instrs = {} for relevant in relevants_without_retn: print ('-------------------dse %#x---------------------' % relevant.addr) block = project.factory.block(relevant.addr, size=relevant.size) has_branches = False hook_addrs = set ([]) for ins in block.capstone.insns: ... elif project.arch.name in ARCH_ARM: if ins.insn.mnemonic != 'mov' and ins.insn.mnemonic.startswith('mov' ): if relevant not in patch_instrs: patch_instrs[relevant] = ins has_branches = True elif ins.insn.mnemonic in {'bl' , 'blx' }: hook_addrs.add(ins.insn.address) elif project.arch.name in ARCH_ARM64: if ins.insn.mnemonic.startswith('cset' ): if relevant not in patch_instrs: patch_instrs[relevant] = ins has_branches = True elif ins.insn.mnemonic in {'bl' , 'blr' }: hook_addrs.add(ins.insn.address) if has_branches: tmp_addr = symbolic_execution(project, relevant_block_addrs,relevant.addr, hook_addrs, claripy.BVV(1 , 1 ), True ) if tmp_addr is not None : flow[relevant].append(tmp_addr) tmp_addr = symbolic_execution(project, relevant_block_addrs,relevant.addr, hook_addrs, claripy.BVV(0 , 1 ), True ) if tmp_addr is not None : flow[relevant].append(tmp_addr) else : tmp_addr = symbolic_execution(project, relevant_block_addrs,relevant.addr, hook_addrs) if tmp_addr is not None : flow[relevant].append(tmp_addr)
patch
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 for nop_node in nop_nodes: fill_nop(origin_data, project.loader.main_object.addr_to_offset(nop_node.addr), nop_node.size, project.arch) for parent, childs in flow.items(): if len (childs) == 1 : parent_block = project.factory.block(parent.addr, size=parent.size) last_instr = parent_block.capstone.insns[-1 ] file_offset = project.loader.main_object.addr_to_offset(last_instr.address) elif project.arch.name in ARCH_ARM64: if parent.addr in [start, base_addr + start]: file_offset += 4 patch_value = ins_b_jmp_hex_arm64(last_instr.address+4 , childs[0 ], 'b' ) else : patch_value = ins_b_jmp_hex_arm64(last_instr.address, childs[0 ], 'b' ) if project.arch.memory_endness == "Iend_BE" : patch_value = patch_value[::-1 ] patch_instruction(origin_data, file_offset, patch_value) else : instr = patch_instrs[parent] file_offset = project.loader.main_object.addr_to_offset(instr.address) block_end_offset = project.loader.main_object.addr_to_offset(parent.addr + parent.size) fill_nop(origin_data, file_offset, block_end_offset - file_offset, project.arch) elif project.arch.name in ARCH_ARM: bx_cond = 'b' + instr.mnemonic[len ('mov' ):] patch_value = ins_b_jmp_hex_arm(instr.address, childs[0 ], bx_cond) if project.arch.memory_endness == 'Iend_BE' : patch_value = patch_value[::-1 ] patch_instruction(origin_data, file_offset, patch_value) file_offset += 4 patch_value = ins_b_jmp_hex_arm(instr.address+4 , childs[1 ], 'b' ) if project.arch.memory_endness == 'Iend_BE' : patch_value = patch_value[::-1 ] patch_instruction(origin_data, file_offset, patch_value) elif project.arch.name in ARCH_ARM64: bx_cond = instr.op_str.split(',' )[-1 ].strip() patch_value = ins_b_jmp_hex_arm64(instr.address, childs[0 ], bx_cond) if project.arch.memory_endness == 'Iend_BE' : patch_value = patch_value[::-1 ] patch_instruction(origin_data, file_offset, patch_value) file_offset += 4 patch_value = ins_b_jmp_hex_arm64(instr.address+4 , childs[1 ], 'b' ) if project.arch.memory_endness == 'Iend_BE' : patch_value = patch_value[::-1 ] patch_instruction(origin_data, file_offset, patch_value)
补充 ollvm混淆的通用解决流程:IDApython脚本跟踪
(1)我们编写相应的IDApython脚本,可以去记录真实寄存器值的变化并记录地址
(2)开启IDA动态调试附加程序,并导入IDApython脚本
(3)触发断点,并开启trace指令跟踪(针对不同的OLLVM混淆可以开启不同级别的trace)
(4)待脚本执行完毕,分析保存的相关文件
(5)分析参数寄存器的逻辑关系,并编写算法还原代码
ollvm混淆解决方案:
基于Unicorn的模拟执行 这里首先我收集大佬编写的三篇相关博客:
(1)unidbg去对抗字符串混淆:AndroidNativeEmu和unidbg对抗ollvm的字符串混淆 | king的博客
(2)unidbg去除ollvm虚假控制流:使用unidbg去ollvm虚假分支反混淆 | king的博客
(3)unidbg还原控制流平坦化:使用unidbg还原标准ollvm的fla控制流程平坦化 | king的博客
简单总结一下核心思路:
字符串混淆: 在.init_array中使用解密函数对字符串进行还原。也就是说。当我们执行完.init_array后。就会将正常的字符串写入内存中。这时我们就得到了真正的字符串了 (1)需要监控内存的读写,模拟运行.init_array,这样发生的内存写入时,基本可以确定是字符串还原函数在写入恢复的字符串
(2)我们需要把所有真实字符串以及写入真实字符串的位置给保存下来
(3)使用脚本将我们的真实字符串再写回so中,写入的so就能直接在ida中打开就看到真实字符串了,保存的address是有一个基址的。
虚假控制流:
虚假分支的混淆会在增加大量的if else分支。增加静态分析的复杂度。但是实际在动态执行的时候。很多if else实际都是没有执行的。所以去掉虚假分支其实就是删除掉那些没有执行到的代码块。
还原: 那么我们只要知道目标函数中,哪些汇编代码执行了,并且记录下执行汇编的address。然后把这些汇编以外的代码全部标记为nop。然后再用ida反汇编看到的结果。就直接是去掉虚假分支的结果了。 (当然现在一些IDA的插件也可以支持去除虚假控制流了,就是利用IDAPython脚本实现)
控制流平坦化:通过符号执行、中间语言分析等方式获取真实块之间的关系
(1)找出所有真实块以及对应的汇编地址,标准的ollvm虚假块中一般只有简单的修改v6的值,其他的基本都是真实块
(2)找出所有真实块的地址后。接着就是顺着逻辑将他们全部串联起来。