


前言
距离第一次接触并使用符号执行CTF——angr使用学习记录_ctf angr-CSDN博客已经三年了,现在再回过头来重温一下
符号执行简述
介绍
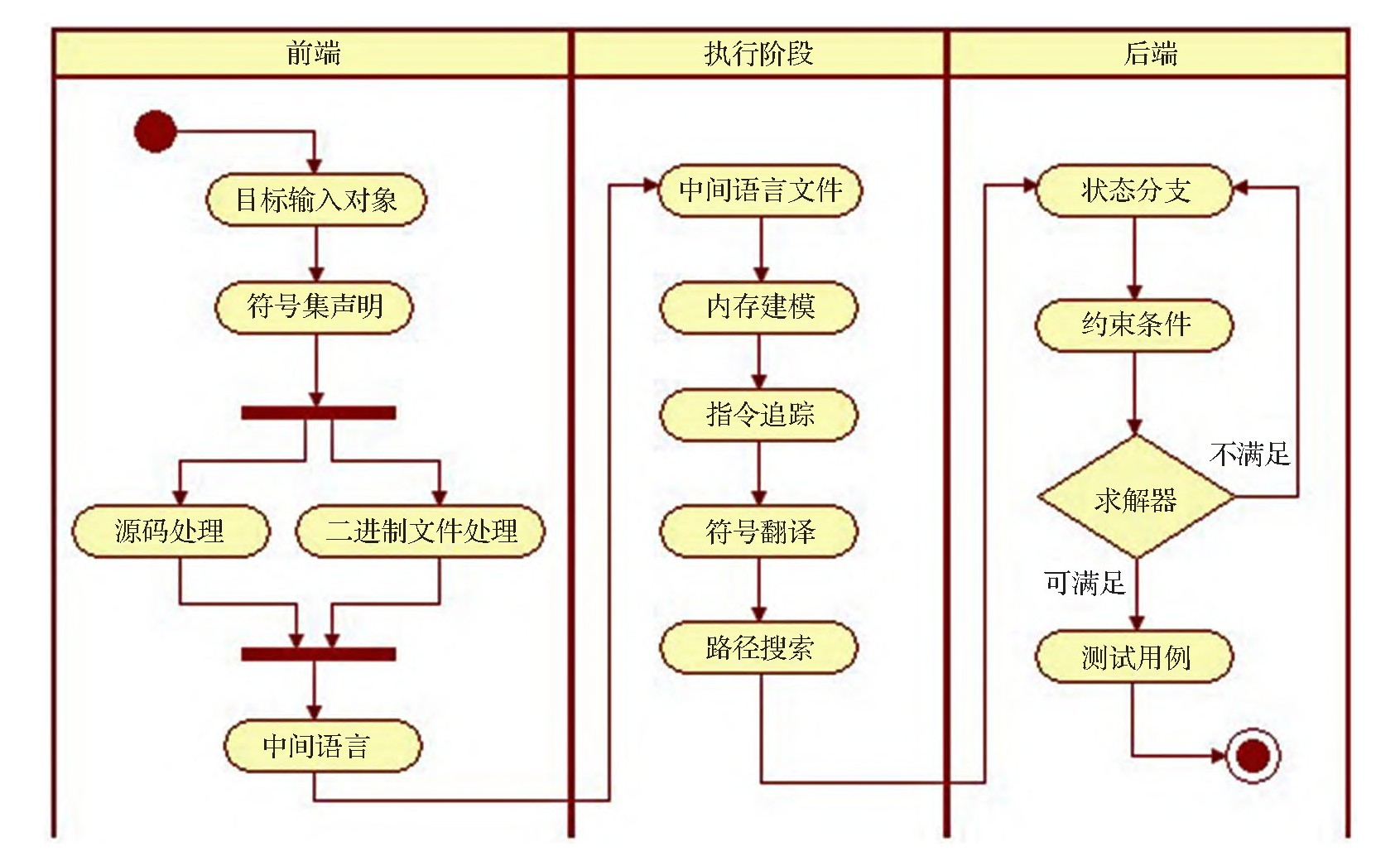
符号执行起初应用于基于源代码的安全检测中,它通过符号表达式来模拟程序的执行,将程序的输出表示成包含这些符号的逻辑或数学表达式,从而进行语义分析。符号执行使用符号值作为输入值,根据程序语义利用符号集对程序变量,表达式和语句进行符号翻译,沿着程序路径执行,通过收集条件送往求解器进行求解,最后的输出值可表示为输入值的符号函数。在遇到状态分支时,相应的分叉探索每支路径状态,收集每支路径上的约束条件,通过约束求解器验证约束条件的可满足性问题。若路径约束可满足,则说明路径可达,并生成测试用例,程序执行到该路径;若约束是不可满足的,则该路径不可达,终止分析。
符号变量: 用符号代替实际值,例如将输入变量 x 设为符号变量。
路径条件(PC): 执行路径上所有分支条件的逻辑与组合,用于约束符号变量的取值。
约束求解器(Constraint Solver): 用来求解路径条件,验证路径是否可行,并生成测试输入。如z3
静态符号执行与动态符号执行的对比
| 特性 | 静态符号执行 | 动态符号执行 |
|---|---|---|
| 执行方式 | 基于代码分析,无需运行程序 | 结合运行时信息,需执行程序 |
| 输入表示 | 完全使用符号变量 | 符号变量与具体值相结合 |
| 路径覆盖 | 目标为覆盖所有路径 | 受初始输入限制,覆盖率依赖动态执行路径 |
| 动态行为支持 | 难以处理(如动态内存、系统调用) | 能更好支持动态行为 |
| 路径爆炸问题 | 严重 | 部分缓解 |
| 使用场景 | 静态漏洞检测、代码验证、开发早期分析 | 动态测试生成、漏洞挖掘、真实环境分析 |
| 工具示例 | KLEE、CBMC | Angr、Driller、SAGE |
挑战
主要还面临着以下挑战:探索路径太多——路径爆炸问题,路径条件太难解决——约束求解问题。
程序执行中路径与分支条件的数量呈指数关系,增加分支的数量导致搜索空间会增大,进一步限制了符号执行的性能。因此,采取合适的搜索策略来提高符号执行的覆盖率,以及减少时间开销尤为重要。
约束求解决定着符号执行的效率。约束求解是一种基于数学理论的分析方法,其问题可描述为一个三元组P=<V,D,C>形式,V表示变量集合V={v1,v2,⋯,vn};D表示中元素的值域集合,即变量的取值范围;C表示约束条件。约束求解问题就是变量在值域范围内取值使得约束条件C可满足的,否则,这约束问题是不可满足的。
angr
一个强大的二进制分析工具。angr 的原理是通过将二进制程序转换为中间表示后,结合符号执行、路径分析和求解器技术,来模拟程序运行。综合了静态分析的结构化视角和动态分析的实时行为追踪能力,能够高效地应对多种复杂的二进制分析任务。官方文档:angr documentation
从angr_ctf练习api的使用
老模板
1 | import angr |
在使用符号变量后,不能通过posix.dump来获取标准输入,而应该获取符号变量的值,simgr.one_found.solver.eval函数可以获取符号变量的值
angr.Project
| API 函数 | 功能 | 常见场景 |
|---|---|---|
angr.Project(filename) |
加载二进制文件,初始化 angr.Project 实例。 |
启动项目,加载目标二进制文件。 |
.factory.entry_state() |
创建从程序入口点(通常是 _start)开始的初始状态。 |
启动符号执行,分析程序主逻辑。 |
.factory.simgr() |
创建 SimulationManager,管理和探索符号执行路径。 |
进行路径探索,寻找满足特定条件的执行路径。 |
.factory.blank_state() |
创建一个空白状态,允许完全自定义内存和寄存器值。 | 模拟特定状态,分析特定函数或跳过程序初始化。 |
.factory.call_state(addr, *args) |
创建直接跳转到目标函数的状态,同时传递参数。 | 跳过程序的主逻辑,直接分析特定函数的行为。 |
.loader |
提供访问加载器信息的接口,包括程序段、符号表和地址映射。 | 分析程序的符号表、段信息或全局变量。 |
.loader.find_symbol(name) |
根据符号名称查找符号对象(如函数或变量)。 | 定位函数入口点(如 main 或 printf)以供进一步分析。 |
.analyses.CFGFast() |
快速构建控制流图(CFG),适用于大部分静态分析场景。 | 分析函数边界、基本块、调用关系等。 |
.analyses.CFGAccurate() |
构建更精确的控制流图,结合符号执行以支持复杂逻辑分析。 | 分析动态分支或复杂的跳转逻辑(耗时较长)。 |
.kb.functions |
提供程序中所有函数的集合,提取的函数信息存储在知识库中。 | 获取函数的入口点、调用地址及详细信息。 |
.arch |
返回二进制程序的架构信息(如 x86, ARM)。 |
匹配目标处理器架构,适配指令集和寄存器配置。 |
.factory.block(addr) |
返回指定地址的基本块对象,包含该块的指令信息和控制流。 | 分析特定地址的基本块逻辑,查看反汇编的指令。 |
.hook(addr, hook_obj) |
在指定地址设置钩子,重定向程序的逻辑到自定义函数或模拟对象。 | 替换系统调用、模拟函数逻辑或跳过某些程序段。 |
.unhook(addr) |
移除指定地址的钩子,恢复地址的原始逻辑。 | 取消对程序特定地址的重定向,恢复正常分析流程。 |
.string(addr, maxlen=100) |
从内存中提取指定地址的字符串。 | 提取程序中的硬编码数据(如密码、路径或消息)。 |
.factory.state_from_addr(addr) |
创建从特定地址开始的执行状态。 | 手动设置分析起点,避免从入口点(_start)执行整个程序。 |
SimState
angr.SimState 类是 angr 框架的核心组件之一,表示符号执行过程中的程序状态。它包含寄存器、内存、约束、文件 I/O 等信息,能够模拟程序的执行流程,追踪路径上的符号化变量以及相应的约束条件。
| API 函数 | 功能描述 | 常见场景 |
|---|---|---|
state.regs |
获取寄存器状态集合,所有寄存器均为符号化位向量(BitVector)。支持通过寄存器名称访问和修改。 |
查看和操作寄存器值,例如修改栈指针(esp)、读取通用寄存器(如 eax)。 |
state.regs.<name> |
通过指定寄存器名称直接访问对应寄存器的值,例如 state.regs.eax 或 state.regs.esp。 |
分析和控制寄存器值,影响程序执行路径。 |
state.mem[addr].type |
通过类型化方式访问内存,type 可以是 char, short, int, long 等。 |
模拟程序对内存的读写操作,提取变量或修改地址值。 |
state.mem[addr].type.concrete |
获取内存中值的具体表示形式(非符号化)。 | 提取内存中实际存储的数据值,例如常量或硬编码数据。 |
state.mem[addr].type.resolved |
获取内存中值的符号化表示形式(符号化位向量)。 | 分析程序中符号化变量的状态或约束。 |
state.memory.load(addr, size) |
从指定地址加载内存,返回大小为 size 字节的位向量(BitVector)。 |
更灵活地获取指定大小的内存数据,适合非标准类型的内存访问。 |
state.memory.store(addr, bitvector) |
将符号化位向量存储到指定内存地址。 | 模拟写入内存的操作,调整或修改程序的内存状态。 |
state.posix.dumps(fileno) |
获取指定文件描述符(如 stdin, stdout, stderr)上的数据流。 |
模拟或分析程序的输入输出交互行为,例如提取输入数据或分析输出结果。 |
state.solver.eval(expr) |
求解符号化表达式的值,返回实际值(具体化结果)。 | 检查寄存器、内存或表达式的符号化解。 |
state.solver.eval_upto(expr, n) |
求解符号化表达式的多个可能值,返回最多 n 个具体值。 |
检查表达式的多种可能解,用于多路径分析。 |
state.solver.satisfiable() |
判断当前状态是否满足所有符号化约束。 | 验证路径是否有效或继续符号执行的条件是否成立。 |
state.globals |
自定义全局变量存储区,允许用户将数据存储到状态中以供后续分析使用。 | 保存和共享分析中提取的额外信息,例如标志位或动态计算结果。 |
示例:栈的符号化:
1 | import angr |
SimulationManager
angr.SimulationManager 是 angr 框架中用于管理和操作多个程序执行路径(SimulationState 对象)的核心组件。它提供了一种高层抽象,用于对符号化执行进行路径分类、过滤、探索以及管理,是分析和控制程序路径执行的强大工具。
两种写法等效
1 | proj.factory.simgr(state) |
angr.SimulationManager 类中使用率较高的重要 API 函数及其功能的详细表格:
| API 函数 | 功能描述 | 常见场景 |
|---|---|---|
simgr.step() |
执行符号化状态的单步操作,更新路径组。 | 模拟逐步执行程序的每条指令或基本块。 |
simgr.explore(find=addr_or_func, avoid=addr_or_func) |
按条件探索路径,找到满足 find 条件且避免 avoid 条件的路径。 |
搜索特定地址或满足特定条件的路径,常用于解题和漏洞挖掘。 |
simgr.run() |
完成符号执行,直到没有更多路径可以探索(或满足指定的终止条件)。 | 对程序进行全面探索,用于分析所有可能的执行路径。 |
simgr.stashes |
路径组的存储字典,包含多个分类路径集合(如 active、found、avoid 等)。 |
检查路径分组情况,提取特定类型的路径以便进一步分析。 |
simgr.active |
当前处于活跃状态的路径集合,表示正在探索的路径。 | 分析程序当前的执行状态或提取路径。 |
simgr.found |
已经找到满足 find 条件的路径集合(通过 explore 或手动操作生成)。 |
获取解决问题的路径,例如找到密码或破解条件。 |
simgr.avoid |
已经找到满足 avoid 条件的路径集合(通过 explore 或手动操作生成)。 |
检查和分析避免的路径,例如危险分支或无解的条件路径。 |
simgr.move(from_stash, to_stash) |
将路径从一个存储分组移动到另一个分组,例如从 active 移动到 found。 |
管理和分类路径的状态,特别是手动调整路径分组以优化分析流程。 |
simgr.filter(func, stash='active') |
按指定条件筛选路径,将符合条件的路径移动到其他分组。 | 用于路径过滤和重分类,例如将特定地址的路径移动到 found 分组。 |
simgr.split(func) |
按条件对路径进行分组,将每个分组放入单独的存储。 | 分类路径,例如按程序逻辑分割路径。 |
simgr.prune() |
清除指定存储中的路径,释放不需要的路径以节省内存。 | 删除不再需要的路径,优化性能或专注于特定分组路径。 |
simgr.drop(stash) |
删除指定分组中的所有路径。 | 清理无用路径集合,提升符号执行效率。 |
simgr.use_technique(technique) |
应用特定的探索技术(ExplorationTechnique),如深度优先或宽度优先搜索。 |
定制符号执行策略,优化路径探索过程。 |
Claripy
Claripy 是 angr 中用于符号化计算和约束求解的关键库,它为符号执行提供了强大的表达式表示、符号求解、符号计算、以及符号约束管理功能。Claripy 处理和操作符号化数据(如变量和内存地址)并提供求解器接口,用于符号计算、约束求解和路径分析。对于我们而言一般不需要直接与其进行交互,但通常我们会使用其提供的一些接口
bitvector - 位向量
位向量(bitvector)是 angr 求解引擎中的一个重要部分,其表示了 一组位 (a sequence of bits)。
以下是优化和扩展后的 Claripy 常用函数和属性表格,增加了详细的描述、常见的使用场景以及新内容:
| 函数/属性 | 功能描述 | 示例代码 | 应用场景 |
|---|---|---|---|
claripy.BVV(value, size) |
创建具有具体值的位向量(BitVector Value)。支持整数或字符串作为值,size 指定位宽。 |
bv = claripy.BVV(10, 32) # 创建一个32位具体值位向量10 |
表示程序中固定值的变量,例如初始化常量、硬编码地址等。 |
claripy.BVS(name, size) |
创建具有符号值的位向量(BitVector Symbol),name 为符号变量名,size 指定位宽。 |
sym_bv = claripy.BVS('x', 32) # 创建一个32位符号位向量 x |
表示程序中未知或可变值的变量,例如输入、环境变量、程序状态。 |
.concat(*args) |
将多个位向量连接成一个更大的位向量。 | result = claripy.Concat(bv1, bv2) # 将两个位向量 bv1 和 bv2 连接成一个 |
组合多个变量或部分数据(如标志位、操作码等)形成一个完整的值。 |
.zero_extend(bits) |
对位向量执行零扩展,将其长度增加指定的 bits 位,用 0 填充扩展部分。 |
extended_bv = bv.zero_extend(8) # 将 bv 扩展 8 位 |
统一位宽,适配不同长度变量的运算需求。 |
.sign_extend(bits) |
对位向量执行符号扩展,将其长度增加指定的 bits 位,用符号位填充扩展部分。 |
extended_bv = bv.sign_extend(8) # 将 bv 符号扩展 8 位 |
处理带符号运算时的位宽适配。 |
.op |
获取位向量表达式的操作类型(如 Add、Sub 等运算符)。 |
operation = sym_bv.op # 返回 sym_bv 的运算类型 |
分析复杂表达式结构,理解操作类型。 |
.args |
获取位向量表达式的参数(子表达式或值)。 | arguments = sym_bv.args # 返回 sym_bv 的操作数 |
获取表达式的子结构,用于符号执行中的表达式简化和优化。 |
claripy.If(cond, true_val, false_val) |
条件表达式,返回当条件为真或假时的不同值。 | result = claripy.If(flag == 1, sym_bv1, sym_bv2) |
表示程序中的条件分支逻辑,例如条件跳转和选择性赋值。 |
.extract(high_bit, low_bit) |
提取位向量中的某些位。 | extracted = bv.extract(15, 8) # 提取 bv 的第 8 至 15 位 |
解析复杂数据格式,如拆解操作码、提取标志位。 |
.reverse() |
反转位向量的字节顺序。 | reversed_bv = bv.reverse() # 将 bv 的字节顺序反转 |
处理不同字节序的兼容性问题,例如大端与小端的转换。 |
.length |
获取位向量的长度(位宽)。 | length = bv.length |
检查变量的大小是否符合预期,用于程序状态分析。 |
.simplify() |
对符号表达式进行简化,尝试减少表达式的复杂度。 | simplified_expr = sym_expr.simplify() |
优化复杂表达式,提高符号执行效率。 |
.is_symbolic() |
检查位向量是否为符号变量(返回 True)或具体值(返回 False)。 |
is_sym = sym_bv.is_symbolic() |
判断变量属性,确定其是否需要约束求解。 |
.resolved |
获取位向量的具体值(BVV),当符号变量已被约束求解时可用。 |
concrete_val = sym_expr.resolved |
将符号变量的求解结果转换为具体值。 |
.concrete |
获取位向量的具体值(int 类型),仅适用于具体值位向量。 |
value = bv.concrete |
检查和操作具体值,例如验证程序中常量的正确性。 |
Claripy ,涵盖了符号表达式的符号计算、符号约束和求解等关键操作。
| 函数 | 功能描述 | 示例代码 |
|---|---|---|
claripy.Bool(name) |
创建一个符号布尔表达式,用于表示符号化的布尔值。 | b = claripy.Bool('b') # 创建一个符号布尔变量 b |
claripy.If(cond, true_expr, false_expr) |
根据条件 cond 返回 true_expr 或 false_expr,类似于三元运算符。 |
result = claripy.If(x == 1, y + 10, y - 10) # 如果 x == 1, 返回 y + 10,否则返回 y - 10 |
claripy.And(expr1, expr2) |
对两个符号表达式进行按位与(AND)运算。 | result = claripy.And(x, y) # 对 x 和 y 执行按位与运算 |
claripy.Or(expr1, expr2) |
对两个符号表达式进行按位或(OR)运算。 | result = claripy.Or(x, y) # 对 x 和 y 执行按位或运算 |
claripy.Xor(expr1, expr2) |
对两个符号表达式进行按位异或(XOR)运算。 | result = claripy.Xor(x, y) # 对 x 和 y 执行按位异或运算 |
claripy.Not(expr) |
对符号表达式执行按位取反(NOT)运算。 | result = claripy.Not(x) # 对 x 执行按位取反运算 |
claripy.Concat(expr1, expr2) |
连接两个符号表达式,形成一个新的符号表达式。 | result = claripy.Concat(x, y) # 将 x 和 y 拼接在一起 |
claripy.LShR(expr, n) |
对符号表达式 expr 进行逻辑右移运算。 |
result = claripy.LShR(x, 4) # 对 x 进行逻辑右移4位 |
claripy.Shl(expr, n) |
对符号表达式 expr 进行逻辑左移运算。 |
result = claripy.Shl(x, 4) # 对 x 进行逻辑左移4位 |
claripy.BVVal(value, size) |
创建一个具有固定值和大小的符号位向量(常量值)。 | value = claripy.BVVal(5, 32) # 创建一个32位的符号常量值 5 |
claripy.symbolic() |
将一个给定值标记为符号化值。返回符号值,表示该值在符号执行中需要被处理。 | symbol = claripy.symbolic(val) # 将 val 标记为符号值 |
claripy.eval_upto(expr, n) |
返回符号表达式的多个解,最多返回 n 个解。 |
solver.eval_upto(x + y, 5) # 求解 x + y 的5个解 |
claripy.solver.Solver() |
创建一个符号求解器实例,用于对符号表达式求解。 | solver = claripy.solver.Solver() # 创建一个符号求解器实例 |
solver.add(expr) |
向符号求解器中添加一个符号约束。 | solver.add(x == 10) # 添加约束 x == 10 |
solver.eval(expr) |
求解符号表达式,返回其具体值(求解后的整数值)。 | solver.eval(x + y) # 求解 x + y 的值 |
solver.satisfiable() |
检查当前符号约束是否可满足,若可满足返回 True,否则返回 False。 |
solver.satisfiable() # 检查当前约束是否可满足 |
solver.unsat_core() |
返回符号求解器中无法满足的最小约束集(unsat core)。 | solver.unsat_core() # 返回最小不可满足约束集 |
claripy.strlen(expr) |
返回一个符号字符串表达式的长度。 | length = claripy.strlen(some_str) # 获取符号字符串 some_str 的长度 |
claripy.strtoint(expr, base) |
将符号字符串转换为整数,base 为进制(如 10 表示十进制)。 |
num = claripy.strtoint(some_str, 10) # 将符号字符串转换为整数 |
hook
在 angr 中,hook 允许用户为程序的特定地址或函数提供自定义的处理逻辑。通过 hook,用户可以拦截程序的控制流,并用自定义的代码替代原有的函数或指令。
常用 hook 函数表格
| API 函数 | 功能描述 | 示例代码 | 常见场景 |
|---|---|---|---|
proj.hook(addr, hook_func) |
将给定地址的原始指令替换为 hook_func 函数的逻辑。 |
def hook_func(state): state.regs.eax = 42 # 设置 eax 寄存器的值为 42 proj.hook(0x400080, hook_func) |
在符号执行时,替换特定地址的指令,实现对程序行为的模拟。 |
proj.hook_symbol(symbol_name, hook_func) |
将给定符号(如函数名)对应的代码替换为 hook_func 函数的逻辑。 |
def hook_func(state): state.regs.eax = 42 # 设置 eax 寄存器的值为 42 proj.hook_symbol('target_func', hook_func) |
在符号执行时,替换函数的实现,用于模拟函数调用。 |
proj.hook_at_addr(addr, hook_func) |
绑定在特定地址上,执行 hook 操作。 | proj.hook_at_addr(0x400080, hook_func) |
通过地址钩住程序,模拟执行特定的内存位置的代码或替换其逻辑。 |
proj.hook_call(addr, hook_func) |
钩住在调用特定地址时触发的操作。 | proj.hook_call(0x400080, hook_func) |
用于模拟对某些函数或操作的调用,替代原本的调用过程。 |
proj.hook_register(register_name, hook_func) |
为寄存器创建钩子函数,替代特定寄存器的操作。 | proj.hook_register('eax', hook_func) |
替代对寄存器的操作,模拟寄存器值的更新。 |
hook_func(state) |
用户定义的钩子函数,接收一个 state 参数并返回新的状态或修改当前状态。 |
def hook_func(state): state.regs.eax = 42 # 设置 eax 寄存器的值为 42 |
用户定义的钩子函数,用于修改符号执行时的状态,如设置寄存器的值、修改内存等。 |
示例:
1 | p.hook(addr=0x08048485, hook=hook_demo, length=2) |
addr 为待 hook 指令的地址
hook 为 hook 的处理函数,在执行到 addr 时,会执行 这个函数,同时把 当前的 state 对象作为参数传递过去
length 为 待 hook 指令的长度,在 执行完 hook 函数以后,angr 需要根据 length 来跳过这条指令,执行下一条指令
优化:
simgr.one_active.options.add(angr.options.LAZY_SOLVES)
对simgr开启LAZY_SOLVES选项,该选项可不在运行时实时检查当前条件能否到达目标位置。虽然这样无法规避一些无解的情况,但可以显著提高效率
1 | #!/usr/bin/env python |
SimFile和SimPackets
| API 函数 | 功能描述 | 示例代码 | 常见场景 |
|---|---|---|---|
angr.SimFile(name, content, size) |
创建一个模拟文件(SimFile),可以包含具体值或符号变量内容,并指定大小。 | import angr, claripy sim_file = angr.SimFile('a_file', content="flag{F4k3_f1@9!}\n") bvs = claripy.BVS('bvs', 64) sim_file2 = angr.SimFile('another_file', bvs, size=8) |
用于创建模拟文件,进行符号执行时模拟文件内容的读取、写入等操作。 |
state.fs.insert(name, sim_file) |
将 SimFile 插入到当前状态的文件系统中。 |
state.fs.insert('test_file', sim_file) |
将模拟文件插入到符号执行的文件系统,模拟程序与文件系统的交互。 |
sim_file.read(pos, size) |
从模拟文件中读取数据,返回数据、实际读取的字节数以及新的位置。 | pos = 0 data, actual_read, pos = sim_file.read(pos, 0x100) |
模拟文件的读取操作,用于获取文件内容。 |
sim_file.write(pos, data) |
将数据写入模拟文件的指定位置。 | pos = 0 sim_file.write(pos, b'new_data') |
用于模拟文件的写操作。 |
sim_file.set_state(state) |
将模拟文件与给定的状态关联,指定哪个状态拥有该文件的内容。 | sim_file.set_state(state) |
将模拟文件与某个特定状态进行关联,确保文件在符号执行过程中的状态同步。 |
angr.SimPackets(name) |
创建一个模拟数据包流(SimPackets),用于模拟与流相关的文件或网络通信。 | sim_packet = angr.SimPackets('my_packet') |
用于模拟流数据(如 TCP 连接、标准 IO 等),帮助处理符号执行中的流操作。 |
sim_packet.read(pos, size) |
从模拟数据包流中读取指定位置的数据。 | sim_packet.read(pos, size) |
用于模拟读取流数据,常用于模拟网络数据流或 I/O 操作中的流数据。 |
sim_packet.write(pos, data) |
将数据写入模拟数据包流的指定位置。 | sim_packet.write(pos, b'new_packet_data') |
用于模拟写入流数据,通常应用于网络协议或 I/O 操作中。 |
state.fs.get(filename) |
获取当前状态下文件系统中指定文件名的模拟文件对象。 | sim_file = state.fs.get('test_file') |
获取已插入的模拟文件,用于进一步的读取、写入等操作。 |
state.fs.remove(filename) |
从当前状态下的文件系统中删除指定文件。 | state.fs.remove('test_file') |
删除文件系统中的模拟文件,常用于清理操作或修改执行路径。 |
sim_file.size |
获取模拟文件的大小。 | file_size = sim_file.size |
获取模拟文件的大小,在处理文件时非常有用,特别是符号执行中需要知道文件大小的场景。 |
sim_file.seek(pos) |
设置模拟文件的读写位置。 | sim_file.seek(0x100) |
用于在文件中移动读写位置,类似于传统文件操作中的 seek 函数。 |
SimProcedure
angr.SimProcedure 类是 angr 提供的一个用于模拟程序中的函数过程的类,它可以用来模拟文件中的某些函数的行为,尤其是在符号执行过程中。通过继承并重写 SimProcedure 类的 run() 方法,用户可以定义自定义的函数行为,这对于替换或模拟二进制程序中调用的特定函数非常有用
SimProcedure 主要 API 函数表格
| API 函数 | 功能描述 | 示例代码 | 常见场景 |
|---|---|---|---|
SimProcedure.run(*args) |
模拟目标函数的行为,必须重写此方法。参数是目标函数的输入。 | class MyProcedure(angr.SimProcedure): def run(self, arg1, arg2): return self.state.memory.load(arg1, arg2) |
用于定义目标函数的模拟逻辑,模拟函数的行为。 |
SimProcedure.ret(expr) |
模拟函数的返回操作,expr 为返回的值。 |
self.ret(result) |
在自定义函数的 run() 方法中模拟函数的返回。 |
SimProcedure.jump(addr) |
模拟跳转到指定地址。 | self.jump(0x400080) |
模拟函数内的跳转,改变程序的执行流。 |
SimProcedure.exit(code) |
模拟程序的退出操作,code 为退出码。 |
self.exit(0) |
模拟程序退出的场景。 |
SimProcedure.call(addr, args, continue_at) |
模拟函数调用,addr 是函数的地址,args 是参数,continue_at 是执行的下一地址。 |
self.call(0x400080, [arg1, arg2], continue_at=0x400100) |
在自定义函数中模拟对其他函数的调用。 |
SimProcedure.inline_call(procedure, *args) |
内联调用另一个 SimProcedure。 |
self.inline_call(AnotherProcedure(), arg1, arg2) |
在当前函数内联调用另一个函数,模拟多个函数交互。 |
Stash
在 angr 中,Stash 是一种状态分类机制,用于将不同类型的符号执行状态组织到 SimulationManager 的不同列表中,以便进行有针对性的分析。每种 Stash 都表示一种特定的状态集合,并支持对状态的筛选、转移、合并、步进等操作。这种设计提高了符号执行的灵活性和效率。
常见的 Stash 类型
| Stash 名称 | 描述 | 典型用途 |
|---|---|---|
active |
活跃的状态列表,表示当前正在执行的状态。 | 默认执行的状态集,用于继续符号执行流程。 |
deadended |
死亡的状态列表。当一个状态无法继续执行时(如无有效指令、无效指针或约束不满足),会归入此列表。 | 分析状态终止原因,例如检测路径的结束条件。 |
pruned |
被剪枝的状态列表。启用 LAZY_SOLVES 时,发现某状态不可满足(unsat),会剪枝到其历史的根源状态,将其及其后代放入此列表。 |
优化符号执行,减少无效路径,提高效率。 |
unconstrained |
不受约束的状态列表。如果 SimulationManager 创建时指定 save_unconstrained=True,则由符号化数据控制指针的状态会归入此列表。 |
分析不受约束的路径,例如利用程序漏洞导致的任意代码执行。 |
unsat |
不可满足的状态列表。当指定 save_unsat=True 时,冲突约束导致的不可满足状态(例如输入同时为 “AAAA” 和 “BBBB”)会归入此列表。 |
发现和分析不可达路径或逻辑冲突。 |
errored |
错误状态列表。状态在执行时发生错误时,状态及其错误会被封装为 ErrorRecord 并放入此列表。 |
调试错误状态,检查程序模拟的异常行为。 |
Stash 操作
| 函数 | 描述 | 示例代码 | 用途 |
|---|---|---|---|
move(from_stash, to_stash) |
在不同的 Stash 之间移动状态。 | simgr.move(from_stash='unconstrained', to_stash='active') |
将不受约束的状态重新激活,进行进一步的符号执行。 |
move(..., filter_func=func) |
通过指定的过滤函数筛选后再移动状态。 | def filter(state): return b"key" in state.posix.dumps(1) simgr.move(..., filter_func=filter) |
提取符合条件的状态(例如包含特定输出),便于后续分析。 |
step(stash) |
对指定的 Stash 中的状态执行一步符号执行操作。 | simgr.step(stash='active') |
控制特定状态集的步进执行。 |
split(func) |
按给定条件将 Stash 中的状态划分为多个组。 | simgr.split(lambda s: s.satisfiable()) |
对状态按约束可满足性等条件进行分类。 |
prune() |
清除特定的 Stash 中的状态以优化资源使用。 | simgr.prune(stash='unsat') |
删除不可满足的状态,提升执行效率。 |
drop(stash) |
删除整个 Stash 的所有状态。 | simgr.drop('pruned') |
清理不需要的状态集,释放内存资源。 |
stashes |
返回所有 Stash 的字典。 | stashes = simgr.stashes |
查看当前 SimulationManager 管理的所有状态分类。 |